
It comes after 8, but before 10
We finally have some more information about the graphics arthitecture found in Skylake.
As the week of Intel’s Developer Forum (IDF) begins, you can expect to see a lot of information about Intel’s 6th Generation Core architecture, codenamed Skylake, finally revealed. When I posted my review of the Core i7-6700K, the first product based on that architecture to be released in any capacity, I was surprised that Intel was willing to ship product without the normal amount of background information for media and developers. Rather than give us the details and then ship product, which has happened for essentially every consumer product release I have been a part of, Intel did the reverse: ship a consumer friendly CPU and then promise to tell us how it all works later in the month at IDF.
Today I came across a document posted on Intel’s website that dives into very specific detail on the new Gen9 graphics and compute architecture of Skylake. Details on the Core architecture changes are not present, and instead we are given details on how the traditional GPU portion of the SoC has changed. To be clear: I haven’t had any formal briefing from Intel on this topic or anything surrounding the architecture of Skylake or the new Gen9 graphics system but I wanted to share the details we found available. I am sure we’ll learn more this week as IDF progresses so I will update this story where necessary.
What Intel calls Processor Graphics is what we used to call simply integrated graphics for the longest time. The purpose and role of processor graphics has changed drastically over the years and it is now not only responsible for 3D graphics rendering but compute, media and display capabilities of the Intel Skylake SoC (when discrete add-in graphics is not used). The architecture document used to source this story focuses on Gen9 graphics, the compute architecture utilized in the latest Skylake CPUs. The Intel HD Graphics 530 on the Core i7-6700K / Core i5-6600K is the first product released and announced using Gen9 graphics and is also the first to adopt Intel’s new 3-digit naming scheme.

This die shot of the Core i7-6700K shows the increased size and prominence of the Gen9 graphics in the overall SoC design. Containing four traditional x86 CPU cores and 1 “slice” implementation of Gen9 graphics (with three visible sub-slices we’ll describe below), this is not likely to be the highest performing iteration of the latest Intel HD Graphics technology.

Like the Intel processors before it, the Skylake design utilizes a ring bus architecture to connect the different components of the SoC. This bi-directional interconnect has a 32-byte wide data bus and connects to multiple “agents” on the CPU. Each individual CPU core is considered its own agent while the Gen9 compute architecture is considered one complete agent. The system agent bundles the DRAM memory, the display controller, PCI Express and other I/O interface that communicate with the rest of the PC. Any off-chip memory requests and transactions occur through this bus while on-chip data transfers tend to be handled differently.
The Skylake-based SoCs can include additional caches like a shared LLC (last level cache) or the eDRAM (embedded DRAM) that made Intel’s Iris graphics so interesting last generation. If an LLC is included on the processor it will connect through the same ring bus interface and each on-die core is allocated a slice of the cache with access granted to the graphics agent too. The distributed LLC reduces apparent latency to external DRAM and increases effective bandwidth.
An optional eDRAM component could be included with the Gen9 graphics as well ranging from 64-128 MB. This memory is not on-die but is on-package, operating at its own clock rate as high as 1.6 GHz. It has separate buses for reads and writes capable of 32-bytes per cycle each. This eDRAM functionality increases for Gen9 over Gen8 implementations and acts as a memory-side cache between the LLC mentioned above and DRAM, again lowering apparent latency and raising effective memory bandwidth. This cache can be shared between the GPU and CPU cores on the chip. A new application for the eDRAM to improve power efficiency is dubbed “low-latency display surface refresh” – giving enabled systems the ability to repeat frame buffer output without accessing system memory at all.
In most ways, the Gen9 graphics and compute architecture is very similar to that of Gen8. There are some refinements in areas of memory hierarchy, compute capabilities and product configuration options however that will give products based on Skylake a significant performance advantage (as our first Core i7-6700K review showcased.)
From the memory angle, Gen9 graphics have several things to take note of. Write performance on coherent SVM (shared virtual memory) is increased thanks to new policies using the last level cache (LLC) while L3 cache capacity has been bumped up to 768 KB per “slice”. Request queue sizes for L3 and LLC have been increased to enhance latency hiding in many cases and texture samplers now support the NV12 YUV format that improves surface sharing capability for compute APIs. The most dramatic change is that move of the eDRAM memory controller to the system agent to allow for display refresh and to act as a memory side cache for the entire chip.
Oh, and let’s not forget that many implementations of Gen9 graphics on Skylake will take advantage of DDR4 for primary system memory rather than DDR3.
Compute capability improvements are a bit more obtuse and include things like thread-level preemption for compute applications, round-robin thread scheduling and native 32-bit atomic operation support.
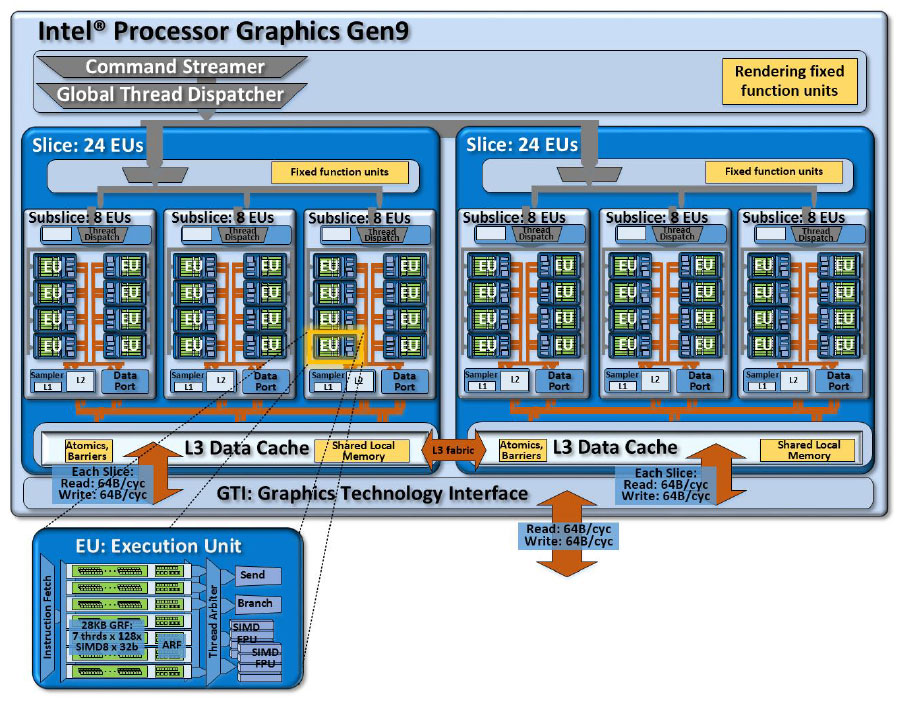
Product flexibility is likely where consumers will see the biggest advantage as it means more specific GPU iterations for each product segment in the market. Gen9 graphics can be designed in 1-3 slice configurations supporting as many as 72 EUs (execution units) and GPU implementations can be modified on sub-slice basis to help with binning and yields. Additional power gating and clock domains can enable drastically improved power efficiency for media playback.
The Execution Unit (EU) itself remains very similar to the Gen8 design we saw on Intel’s previous generation of processors.

Each EU can support 7 threads and has 128 general purpose registers. They support SMT and IMT multi-threading and utilize a pair of SIMD FPUs for both floating point and integer based computing and are capable of 16 32-bit floating point operations every cycle.

In the Gen9 graphics architecture these EUs are organized in subslices which can be architected to any number of EUs. However, documentation shows that for most purposes Intel has settled on 8 EUs per subslice as the best balance of hardware and efficiency. Each subslice contains its own local thread dispatcher and its own instruction caches. Sampler units (normally called texture units with other GPUs) and a data port (load/store) are included on each subslice as well. Compared to Haswell-based Gen7.5 graphics architecture, both Gen8 and Gen9 lowered per-subslice EU counts from 10 to 8, improving local bandwidth internally on the structure.
The texture/sampler units in each subslice are read-only memory fetch units to sample texture and image surfaces. It has dedicated L1 and L2 cache and supports common compression and decompression formats while doing the work for texture filtering including anisotropic.

A combination of subslices is called, as you might expect, a slice. For most of the Gen9 based products there will be three subslices included in each slice for a total of 24 EUs. Just like we see in other discrete GPU solutions, you will likely see some instances of Intel disabling EUs in order to improve yields, power consumption or just to create market differentiation.
Additional logic is included in each slice for thread dispatch, additional L3 cache, and fixed function logic for atomic operations. For the Gen9 graphics architecture that L3 size has increased to 768 KB. Application context will determine how much of this L3 cache is distributed to data cache, system buffers for pipeline handling and simple shared local memory. For example, 3D workloads tend to need more system buffers for fixed function pipelines while compute applications the need for data cache is heavier.
Each subslice has individual access to the L3 cache for both sampler/texture and data connectivity and that enables 64 bytes per connection per cycle, or 192 bytes total, which can be accessed in aggregate. Filling that cache only occurs at 64 bytes per cycle should there be a cache miss.
A total product architecture is a combination of one or more slices with additional front end logic for command submission, fixed function hardware for 3D and media pipelines as well as a dedicated graphics technology interface (GTI) for accessing the rest of the components on the SoC.

The above diagram shows the Intel Gen9 graphics implementation on the Core i7-6700K, utilizing 24 EUs. The command streamer takes submitted work from driver stacks and properly routes commands to the appropriate units. As compute workloads arrive the thread dispatcher is responsible for thread distribution on EUs based on load.
Unlike the rest of the processor that needs to communicate through the ring bus, the Gen9 graphics architecture is able to talk with the LLC, eDRAM and even primary system memory through the GTI. It also allows the GPU and CPU to communicate efficiently and gives the CPU cores access to the global memory atomics. The GTI is also responsible for interfacing the GPU clock and other SoC clock domains to implement power management.

Possible larger configurations for Gen9 graphics on Skylake
The bus between the GTI and the LLC is adjustable based on performance needs and power concerns. As in Gen8 designs, a processor can utilize 64 byte per cycle reads and writes for the best performance or a product design could implement a 32 byte per cycle write limit to improve power efficiency at a cost of performance.
New to Gen9 graphics is full support for global memory coherency between the CPU cores and the GPU. Along with that change comes support for the new Intel VT (Virtualization Technology) Directed I/O updates that include support for shared memory between the CPU cores and graphics architecture in a virtualized environment. This opens up some interesting opportunities for new platform designs going forward.
These new mechanisms to maintain memory coherency enable better support for emerging new APIs like OpenCL and DirectCompute. The net result is that pointer-heavy applications and structures can be shared directly between the CPU cores and GPU infrastructure without the performance crippling and power hungry copying of data. This has long been the promise of heterogeneous computing paradigms and Intel’s Gen9 graphics and compute architecture get us closer to that as a universal standard.

This diagram gives us a great view of the entire memory hierarchy on a Skylake + Gen9 SoC with per-clock bandwidth data labeling each connection pathway.
As of today, with only a single configuration of the Gen9 graphics actually announced, the data in the table below is woefully incomplete. But it does give us the ability to measure and estimate performance capability of the current Intel HD Graphics 530 and future designs with more EUs.

At 384 FLOP/cycle and peak clock rate of 1.15 GHz according to Intel’s website, that give the Intel HD Graphics 530 a peak throughput of 441.6 single precision GFLOPS. That is great for an Intel integrated GPU but only puts it between the performance available to a GeForce GT 720 and GT 730 when compared to discrete components and a little more than half the peak performance of AMD’s Kaveri APUs (845 GFLOPS).
However, if you extrapolate from the 2- and 3-slice configurations of Gen9 that we assume will happen at some point, banking on the same frequency, Intel could have future parts running into the 880 GFLOPS and 1.32 TFLOPS territory. Add in the benefits of the eDRAM on future Iris designs using Skylake and you will have some very competitive integrated solutions from Intel this year.
Our overall picture of Intel’s Gen9 graphics and compute architecture, and Skylake in general, just got a little clearer with the release of this information today before IDF. I still need to know what other SKUs and configurations are going to be built based on these designs and if Intel will indeed build a processor with a 72 EU implementation – it would be an interesting move for a company that hasn’t put the same emphasis on processor graphics that AMD has, traditionally.
Expect much more on Skylake and the future of Intel’s 6th Generation Core products this week from IDF!





Forget about CPU cores both
Forget about CPU cores both Intel’s and AMD’s, I’m much more interested in the total compute power of the GPU, and how it compares to both AMDs ACEs, or Nvidia’s equivalent. I do a lot of rendering of single images with millions of polygons, and with the Ray Tracing turned on. I’m much more interested in the FPUs on the GPU and their ability to handle Ray tracing calculations by the trillions, and not simply billions, and that’s where AMD and Nvidia have the edge over any of Intel’s high priced underpowered GPU technology. I need the latest ACE type technology with the ray interaction calculations able to be done on the GPU, and forget about the CPU! I have a core i7, and that takes forever running at 100%, all 4 core/8 processor threads with ray tracing workloads. The HSA ability to run complex tasks on the GPU is being implemented by even the open source graphics packages, and office suits, and even Intel’s Xeons can take to much time doing the ray tracing calculations compared to what can be done on the GPU. I do not have a need going forward for anything more powerful than Carrizo’s cores, and with even more hardware improvement coming to AMD’s ACE units and Nvidia’s equivalent, who cares about CPUs anymore for graphics workloads, maybe for gaming but not for non gaming graphics workloads.
It’s great to see improvements in CPUs but CPUs are too costly and resource constrained compared to GPUs for the applications that I use. GPU’s via HSA types of improvements are truly coming into their own for more than just graphics workloads now that the software ecosystem is catching up to the latest in GPU hardware.
Intel should stop playing
Intel should stop playing around and come out with a discrete GPU already. They would do well in both gaming and compute tasks. It would be lovely to have a 3rd option to spur the Green and Red team on too.
Xeon Phi (Knights xxx) is the
Xeon Phi (Knights xxx) is the precursor to the future of Intel IGP/GPU. Stacked MCDRAM, X86, ray-tracing, other buzzwords… First the compute world will use them, then the professional rendering crowd will use them, and then we might see a consumer product. Most likely is that the above features will just trickle down into IGP. Intel MCDRAM vs AMD HBM vs NVIDIA HBM…
No the entire Xeon phi line
No the entire Xeon phi line are the direct descendants of the failed Larrabee project, and the total number of FP resources on the Xeon Phi’s pale in comparison to the numbers on AMD’s and Nvidia’s GPUs. Ever wonder why AMD’s and Nvidia’s GPUs are clocked lower that the Xeon Phi yet still manage to best it in total SP/DP FLOPS. And Intel lacks some of the IP, and Licenses to the IP for GPUs that AMD and Nvidia possess. Intel is far behind the curve, and those ACE units from AMD, and whatever Nvidia’s equivalent is called, are able to do more of the CPU type calculations with each new generation of AMD’s or Nvidia’s GPU microarchitectures!
Soon it will be goodby to the CPU for any and all graphics workloads, and many graphics workstations will be able to get buy with the basic level of CPU power. Current and future GPUs from AMD and Nvidia can dispatch their own kernels and workloads themselves, and even dispatch workloads back to the CPU. Expect that both AMD and Nvidia will remain far ahead of Intel in GPU technology, and that both AMD’s and Nvidia’s GPUs will be acquiring more of the abilities and the logic that was once the domain of only the CPU.
Intel will be at a definite disadvantage once Zen arrives, and future Zen APU SKUs beyond are expected to directly dispatch FP instructions from the CPU to the GPU, so expect the further merging of the CPU with the GPU in AMDs future APUs, and that includes complete cache coherency between CPU and GPU on the APU, and off the monolithic Die/s via the Interposer for APU systems on an interposer. That interposer technology is going to allow for even more APU power to be added to systems for gaming, and other workloads.
Your 3rd paragraph is
Your 3rd paragraph is ridiculous. You’re a dumb clown and you’re dreaming. Go buy more computer hardware that you’ll never use nerd.
It wont happen, Intel isn’t
It wont happen, Intel isn’t interested in discrete graphics cards, just creating drivers would be painfull, Nvidia and AMD have years of experience already, thats why they killed off Larrabee around 5 years ago.
If 3 slices is about 1.3
If 3 slices is about 1.3 TFLOPS, why couldnt Intel make a discrete GPU out of 12 slices? Its theoretical FLOPS would be about 5.2 TFLOPS which is the same as a 780ti, except this is 14nm.
because you need
8 million
because you need
8 million transistors.
4x die size
300 Watt TDP
Liquid cooling
500 GB/s memory
14 nm is not going to do much on the above requirement.
besides Discrete is dead. mobile is king now.
Gamers are not the market. There is no growth in PC.
Gaming is a bright spot you
Gaming is a bright spot you ignorant retard.
I realize that gamers are not
I realize that gamers are not the market.
However, GP100 will be the next Geforce as well as being used in servers and supercomputers.
Knights Landing is 3 TFLOPS DP 6 TFLOPS SP and i was wondering what an Intel discrete GPU would be like.
There may be no growth in PC but the growth in datacenters and supercomputers means plenty of defective GP100s to become Titans and Geforces.
Outlandish made up
Outlandish made up requirements are outlandish.
green team forever!
green team forever!