Clean Sheet and New Focus
AMD has taken the wraps off of architectural details of Zen.
It is no secret that AMD has been struggling for some time. The company has had success through the years, but it seems that the last decade has been somewhat bleak in terms of competitive advantages. The company has certainly made an impact in throughout the decades with their 486 products, K6, the original Athlon, and the industry changing Athlon 64. Since that time we have had a couple of bright spots with the Phenom II being far more competitive than expected, and the introduction of very solid graphics performance in their APUs.
Sadly for AMD their investment in the “Bulldozer” architecture was misplaced for where the industry was heading. While we certainly see far more software support for multi-threaded CPUs, IPC is still extremely important for most workloads. The original Bulldozer was somewhat rushed to market and was not fully optimized, while the “Piledriver” based Vishera products fixed many of these issues we have not seen the non-APU products updated to the latest Steamroller and Excavator architectures. The non-APU desktop market has been served for the past four years with 32nm PD-SOI based parts that utilize a rebranded chipset base that has not changed since 2010.

Four years ago AMD decided to change course entirely with their desktop and server CPUs. Instead of evolving the “Bulldozer” style architecture featuring CMT (Core Multi-Threading) they were going to do a clean sheet design that focused on efficiency, IPC, and scalability. While Bulldozer certainly could scale the thread count fairly effectively, the overall performance targets and clockspeeds needed to compete with Intel were just not feasible considering the challenges of process technology. AMD brought back Jim Keller to lead this effort, an industry veteran with a huge amount of experience across multiple architectures. Zen was born.
Hot Chips 28
This year’s Hot Chips is the first deep dive that we have received about the features of the Zen architecture. Mike Clark is taking us through all of the changes and advances that we can expect with the upcoming Zen products.
Zen is a clean sheet design that borrows very little from previous architectures. This is not to say that concepts that worked well in previous architectures were not revisited and optimized, but the overall floorplan has changed dramatically from what we have seen in the past. AMD did not stand still with their Bulldozer products, and the latest Excavator core does improve upon the power consumption and performance of the original. This evolution was simply not enough considering market pressures and Intel’s steady improvement of their core architecture year upon year. Zen was designed to significantly improve IPC and AMD claims that this product has a whopping 40% increase in IPC (instructions per clock) from the latest Excavator core.

AMD also has focused on scaling the Zen architecture from low power envelopes up to server level TDPs. The company looks to have pushed down the top end power envelope of Zen from the 125+ watts of Bulldozer/Vishera into the more acceptable 95 to 100 watt range. This also has allowed them to scale Zen down to the 15 to 25 watt TDP levels without sacrificing performance or overall efficiency. Most architectures have sweet spots where they tend to perform best. Vishera for example could scale nicely from 95 to 220 watts, but the design did not translate well into sub-65 watt envelopes. Excavator based “Carrizo” products on the other hand could scale from 15 watts to 65 watts without real problems, but became terribly inefficient above 65 watts with increased clockspeeds. Zen looks to address these differences by being able to scale from sub-25 watt TDPs up to 95 or 100. In theory this should allow AMD to simplify their product stack by offering a common architecture across multiple platforms.

In overall power per cycle, Zen is very similar to what we see with current Carrizo parts. It will consume as much power at 3 GHz while providing that 40% boost in performance. This is a tremendous efficiency gain, but it is not entirely done by design alone. Carrizo is still being produced on GLOBALFOUNDRIES 28nm HKMG process while Zen will be introduced on the new 14nm LPP process that has been ramping up at GF. While design does play a significant part, AMD is getting a near two generation jump in process technology to apply to the Zen architecture.

The above list shows many of the improvements that Zen has received as compared to the previous Excavator based products. It truly is a clean sheet design that borrows very little from the previous generation other than feature support (SSE, AVX, FMA3, etc.). Of interest is the drop of support of FMA4. This was introduced some years ago by AMD and included FMA3 functionality. FMA4 was not easy to implement effectively and never saw wide support in software. Intel championed FMA3 and it is a more effective implementation and has wider software support.
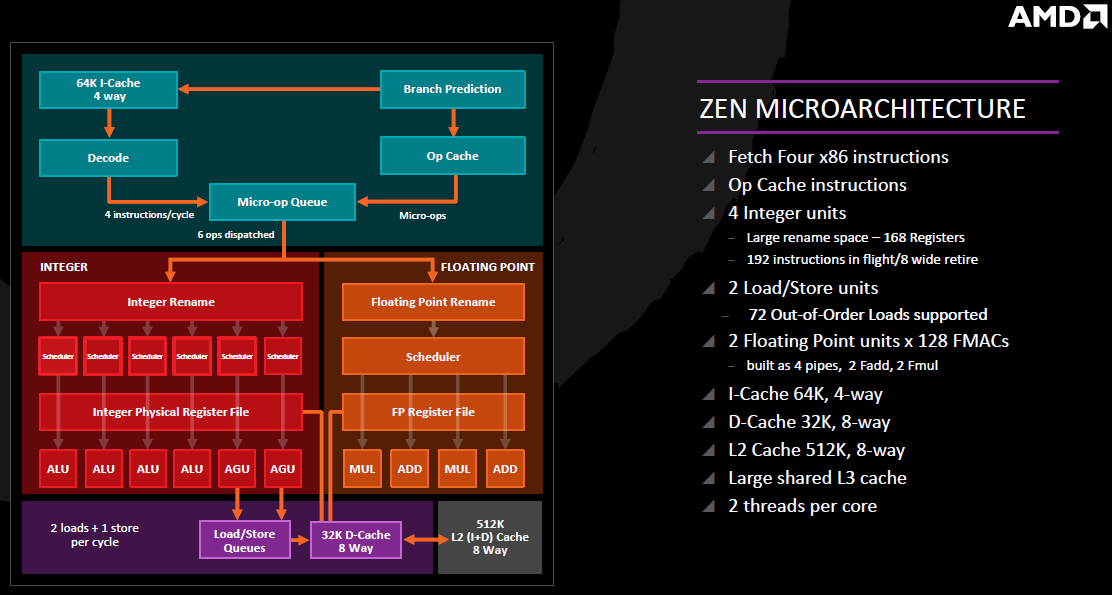
The front end of the Zen CPU was again changed dramatically from previous generations. There are many new additions here that help keep the execution units fed. Engineers were able to improve the L1 and L2 cache systems to offer nearly double the bandwidth of the previous generation as well as lower latency and improve accessibility from other cores.





“Cautiously Optimistic” is
“Cautiously Optimistic” is how i’m proceeding until i see impartial benchmarks.
Same here. I get the feeling
Same here. I get the feeling that AMD went through and dismissed thousands of benchmarks until they finally discovered this ONE benchmark (Blender render) that produced favourable result.
Yeah, it is an interesting
Yeah, it is an interesting choice. Talked to some folks around the industry about it, and there was a lot of shrugging. Obviously gonna need a lot more 3rd party benchmarks and reviews before we have a better opinion of overall performance. But at least one thing is for sure… it is a whole lot better than Bulldozer!
Yea AMD has picked some
Yea AMD has picked some suspect things for benchmarks recently like what they did with Fury chip’s or AOTS for 480.
So, AMD shows improvements
So, AMD shows improvements and all you can think of is how to shit on it? very classy move
He’s being skeptical based on
He’s being skeptical based on misleading advertising at previous events like this.
And your response is ‘classy’
why?
Hang around for awhile and
Hang around for awhile and you’ll see just how deep his anti-AMD/pro-nvidia hole goes.
I suspect any statement that
I suspect any statement that doesn’t gush all over AMD’s products sound “anti-AMD” to you.
Agreed. I expect overall in
Agreed. I expect overall in all, four core Haswell-eske performance for the eight core.
No Blender Render is always
No Blender Render is always done on the CPU, for GPU rendering Blender uses is Cycles renderer with the materials and other settings having to be explicitly set up for any cycles rendering. So Blender CPU render will always max out the CPU core’s threads at 100%, and look at how long it took those lousy x86 core from both AMD and Intel to do a simple render task. Any Nvidia/AMD GPU would have made that render look like an instantaneous snap shot in comparison to the time it took both CPU to render that simple task. So Blender Render is a good way to show one CPU’s performance relative to another CPU performance by taxing both CPU cores/threads 100% for rendering workloads. That just go to show how piss poor CPUs are at rendering!
CPU are the Mooks of the graphics world, they need GPUs to be able to game, and even these CPUs had to have some identical GPU assistance to RUN the OS’s graphics/compositor calls and GUI, because we all Know that CPUs(Suck) are not good at Graphics! I can not wait for GPUs to get some dedicated ray tracing hardware and free all graphics workloads from the CPUs that so suck at graphics.
wow, talk about off-topic.
wow, talk about off-topic.
GPUs rule CPU Mooks drool!
GPUs rule CPU Mooks drool! CPU cores the great Rip off of the computing ages. GPU have way more FPUs/Flops than any CPU scrubs!
Somebody get this kid some
Somebody get this kid some pom-poms.
CPUs suck at graphics and
CPUs suck at graphics and gaming, just you try and game without the help of a GPU! And with AMD adding more CPU like features to its GCN ACE units there will be even less need for CPUs for graphics/gaming in the future. Now get to your janitorial duties you damn dirty CPU Ape, and leave the Graphics and gaming to the processors with the most FPUs/Flops. Really $1700 dollars for a CPU with only 10 cores, even more for 24 cores, that’s highway robbery!
GPUs more cores/FPUs/Flops for the dollar!
Except that GPUs arent very
Except that GPUs arent very good at a lot of things, and in a lot of cases x86, ARM, SPARC or vector CPU cores are necessary.
Stuff can be offloaded to GPUs, FPGAs etc but they dont typically replace CPUs for everything.
Oversimplifying and saying GPUs offer better value for FLOPS is stating the obvious but leaving out half the story.
And Imagination technologies
And Imagination technologies has added dedicated Ray Tracing functional units to its PowerVR IP portfolio. So no CPU cores needed for that Ray Tracing done on any PowerVR GPUs that include the Ray Tracing IP. Also for AMD those ACE/Compute Units are actually becoming more CPU like with each new GCN generation from AMD! So expect more CPU like functionality from AMD on its Vega GPUs to provide more in the way of asynchronous compute features for the consumer and HPC/Workstation/Server accelerator markets, including AMD’s HPC/Workstation/Server APUs on an interposer designs with a big fat Greenland/Vega die 16/32 Zen cores and HBM2.
Put 2 of those 16 Zen cores/Vega/HMB2 HPC/Workstation/Server APUs on an Interposer in place of the GPUs on Apple’s Mac Pro, right where GPUs are now, and there will be no need for any mainboard Xeon CPU, as the APU will have it all CPU/GPU/HBM2. Dedicated Ray Tracing functional blocks are eventually going to be provided on GPUs from all makers, or GPUs will get more of the CPU like functionality in their shader hardware and do more of Ray tracing work on the GPU that was traditionally done on the CPU, and even now there is software from both AMD and Nvidia designed to accelerate Ray Tracing on the GPU, via OpenCL/Cuda/other HSA methods.
Ok you brought up
Ok you brought up asynchronous compute, raytracing specific ASICs, and putting two APUs(just a CPU with a big integrated GPU). The point being?
For some applications the GPU cores will be idle. For some the CPU cores will be. Not everyone is rendering or playing games. You do realize that right?
Having an APU with HSA is a good idea, but putting two of them on an interposer would be difficult to package and very expensive.
Not every kind of code scales well across tiny simple cores. Thats why Intel has Xeons and Xeon Phis, and thats why they bought Altera and Nervana.
NEC has the CPU with the highest single core performance in their SX-ACE, which is extremely efficient with real world code and HPCG. The successor CPU is due out in 2017.
Fujitsu just announced that they are making their exascale system based on ARM V8 with 512bit SIMD SVE units, in an all CPU system. Intel is similarly working on pre exascale architectures that are all CPU.
They also did something very smart by making the Skylake Purley Xeons the same LGA 3647 socket as Knights Landing.
CPUs are becoming more diverse and they are having things like integrated FPGAs added to them, but theyre as important as ever. APUs on interposers cant do everything. Im not sure what your point with raytracing is. It is very easily GPU accelerated. Could you explain why its so important though?
“For some applications the
“For some applications the GPU cores will be idle”! And AMD’s GCN CUs will be available for compute also! So for any other applications, or parts of the game, running can also make use the GPU for compute. Some people record their gaming sessions so any unused GPU compute can take up the slack elsewhere.
The HPC/Server/Workstation market will pay extra for those APUs fully on an interposer SKUs and do so for the power savings alone over the devices’ useful life! The HPC/Server/Workstation will buy AMDs APU/Interposer SKUs for that market by the hundreds of thousands and those sales volumes will create an economy of scale that will fully amortize any extra R&D development costs in the server/HPC/Workstation market, and thus lead to a much lower cost for the consumer derived versions of these HPC/Server/Workstation APUs on an Interposer SKUs.
That’s is how the economy of scale works for the computing market, with the new costly technology and R&D paid for by the HPC/Server/Workstation market that pays the higher margins and produces the revenues that pay the initial new technologys’ costs down until that technology is more affordable for the consumer markets. The Government Exascale initiative R&D grants will also help with the funding for the new APU/Interposer R&D, so even the business markets do not have to foot the total bill to amortize all that new technology costs for R&D and production tooling for interposers/etc!
You think that because a GPU
You think that because a GPU can render a game frame several times a second that the time it took in this render is poor?
You realize games are highly optimized for real-time rendering, with a lot of tricks and compromises for them to be rendered in real time? Detailed games models such as characters are made using software such as ZBrush (which work on the CPU BTW) with billions of polygons and a then low-poly model is created with all the smaller details faked in the textures, because a game would simply crash trying to display this single 3D model. Games takes farther objects and swap them with simplified models of said objects when they get away to help render less stuff. Games also has very limited real time lighting, most of the lighting is pre-rendered, even in games that appears to have dynamic lighting, most of the time they are just swapping lightmaps. Also, games tend to use a technique called Occlusion culling, which won’t render objects that are behind another object. Games also uses simple Shadow Maps for shadows instead of the much more complex and more accurate raytraced shadows that are used in 3D movies. Reflections, such what you would see on a metallic surface, are not real reflections, they are made using what we call a Cube map, which is a flat projection of the room in a simple cube texture. I could go on and on.
In other words, games are rendered on real time, not because they are using the GPU, but because they got less stuff together render to begin with. GPUs are great at quickly rendering optimized 3D scenes, while, as far as I know, CPU is better for more complex stuff with physically accurate lighting and all that stuff. Don’t confuse real time graphics with high end 3D scenes to be rendered.
You know, Pixar’s render farms uses CPUs for a reason.
Really that was ages ago, and
Really that was ages ago, and now the render farms/cloud servers are full of GPUs with very little numbers of CPUs doing anything other than sending the work over to the GPUs and staying the hell out of the way while the GPUs do the graphics workloads. I’m talking about Graphics rendering not games rendering, and yes games rendering is not as intensive with gaming’s simple low polygon count mesh models and scenes and lower resolution textures.
That Zen/Intel/Blender Benchmark Scene was relatively low resolution by GPU standards and it still took some time for an 8 core Zen and Intel CPU to do what a GPU could do in very short order. Future GPUs are going to be able to dispense with need for any help from CPUs, as the GPUs compute units become able to do more CPU like workloads on the GPUs hardware. Ray Tracing is the Next Big thing to get some specialized GPU units, and the PowerVR Wizard SKU already has specialized Ray Tracing functionality to do the Ray interaction calculations on the GPU.
Are you sure, that with this
Are you sure, that with this uarch, AMD really had to walk a long way to find one outlier benchmark?
Blender is actually showing off one of AMD’s worse parts – the FPU. BDW has 2x the raw FP throughput, if code uses it properly.
Or they wanted something
Or they wanted something visual to show during the presentation
that everybody could understand.
AGREE
AGREE http://www.anandtech.com/show/10585/unpacking-amds-zen-benchmark-is-zen-actually-2-faster-than-broadwell
I’m having one!
Should be a
I’m having one!
Should be a good replacement for my ageing FX 8370
You’ll get two major
You’ll get two major improvements there – not just CPU performance, but all of the newer I/O stuff too. I have an OC’d i7-2600K and will be keeping an eye on Zen for the same reasons..
As long as it has equal or
As long as it has equal or greater performance than my i7 3770K, I’ll be picking up the 8C/16T Zen CPU.
I’m not really willing to shell out $1,110~ USD for an 8core CPU, but I need to upgrade to something soon because Intel quad-cores are junk if you need to encode/render/record in a timely manner. Encoding two videos at once makes my 3770K choke.
Come on Zen, please don’t be shit.
Sounds like you are one of
Sounds like you are one of the few that could use the extra cores from a CPU as encoding is about the only application that saturates my 4790K CPU. Yet I seriously doubt that AMD will continue with their practice of the last few years to have inexpensive CPUs. How much will you be willing to pay for a 8 core Zen?
I’m expecting i7 pricing.
I’m expecting i7 pricing.
Maybe for the 8C/16T, but not
Maybe for the 8C/16T, but not for the 4C/8T. Don’t forget, every 4C/8T Intel sell uses ~50% of its area on integrated graphics, which 95% of desktop gamers don’t use anyway.
The 4C/8T Zen won’t do that. So I’d expect it to be considerably cheaper than the cheapest 4C/8T i7. Personal guess, by ~1/3rd. So more like $200 than $300.
Wouldn’t be surprised if the 8C/16T came in at <$400 either. As it probably wont be exactly 2 x as large, the uncore being ~the same size. So ~$350-400 probably. Frankly I have no idea why people think AMD *have* to charge the same prices as Intel, as long as they make their 40% gross margin target, they can charge whatever they want.
I think most of us think that
I think most of us think that financially AMD needs the money. I expect that much like the past they will try to beat Intel on price:performance but since their parts will be significantly faster than they have been recently that will mean higher prices than they currently charge.
Sure it will. But as the
Sure it will. But as the FX-8350 is ~$160, what part of ~$200-$400 for the Zen series wouldn’t be higher priced ? Or supply much higher ASPs ?
It’s more than a few, and I’m
It’s more than a few, and I’m looking forward to the time where for rendering(ray tracing) and encoding workloads than lend themselves to parallel workloads that CPUs can be dispensed with entirely. Imagination Technologies has dedicated ray tracing functional blocks on some of its PowerVR GPUs, and CPUs are really over priced for the measly amount of cores/FPUs that they provide. I’m hoping for GPUs to get enough CPU like functionality that they do not need CPUs at all for most Graphics/Gaming workloads!
Were you a regular at MaxPC?
Were you a regular at MaxPC? I think I remember your name.
There are some hints that
There are some hints that DX12 games will start to benefit from more than 8 threads. The Ashes of the Singularity game/benchmark is one (moderate scaling to 12 threads, minor scaling to 16). Civilization V+ also likes a lot of cores due to the amount of simulation going on there. But these are still few and far between …
“AMD seems to have rebranded
“AMD seems to have rebranded “modules”
AMD has not rebranded “modules” to “complexes” as in AMD’s modules 2 cores shared execution resources! So with Zen the only sharing is of the last level cache, so each complex of 4 FULL FAT Zen cores with their own FPUs, integer, decode, L1 caches, L2 cache etc. The Zen complex of 4 cores is also optimized for cache sharing among the Zen cores in the complex with full cache access across the 4 cores taking the same number of steps and allowing for the cores to work efficiently as a unit for more complex tasks.
With Zen there is no CPU core competition/contention for resources with any other Zen cores in the complex, and at the processor thread level there is plenty of execution resources to allow for each processor thread to get at both integer and floating point resources with very little in the way of delays. The L1 caches are also write back caches, and are only written to the L2 at the time of eviction from L1, keeping the cache interconnect subsystem from being communication bound. Each SMT ZEN core can dispatch up to 6 INT micro-ops and 4 FP micro-ops per cycle.
A Zen Complex is a complex of 4 FULL Zen cores that only shares a level 3 cache among the 4 cores in the complex, hardly anything near to being comparable to the old CMT “Module” designs of bulldozer etc.
Semantics? I will be curious
Semantics? I will be curious if they will split a "complex" much like they didn't split a "module".
Well the complex appears to
Well the complex appears to only be sharing the l3 cache, and there appears to be some sort of ring/other topology bus/fabric there to have the cores able to get at each others Caches with no difference from core to core in the 4 core complex. So maybe there is still more info to be revealed, but the individual cores appear to have their own Full CPU core resources unto themselves save the L3 cache! And I’m getting curious about what type of internal BUS/fabric may be there to connect up the individual CPU cores in the complex as there may be more than just simply the sharing of a L3 cache, as the inter-CPU bus snooping and cache access has to be mediated by some from of coherent fabric/BUS subsystem.
Look at Intel’s ring bus on SandyBridge, as that sort of thing may be there for Zen as well, but AMD is saying that the complex is a scalable entity so AMD has this complex and how does it actually scale, and what sort of subsystem is intrinsic to the 4 core “Complex” to allow for it to be scalable to 8, 12, or more in 4 core increments, maybe some other IP that AMD has on hand has been incorporated as a secret sauce that has yet to be revealed.
This question is foremost
This question is foremost upon our minds. What are they using for interconnects, and can they subdivide a complex without breaking functionality? My guess, and it is probably a bad one, is that they have things so tightly intertwined to decrease latency that going with a 2 core/4 thread or 1 core/2 thread subset might not be entirely feasible. I don't know for sure…
Didn’t AMD buy a company that
Didn’t AMD buy a company that produced a high speed interconnect material a few years ago?
AMD owns the Freedom Fabric
AMD owns the Freedom Fabric IP still I think.
Anandtech has their deep dive
Anandtech has their deep dive into Zen published, with some type-o errors but it is a really deep dive with new information. What fabric IP that AMD used is still a mystery that may have to wait for closer Zen’s actual release date! But this SKUs sure looks like it may be derived from half a 16 core Zen Server SKU, and the Zen APUs scheduled for release in 2017 for laptop/mobile may have some uncore/other differences as always, same for Intel with the differences between its various x86 mobile, desktop, server/HPC SKUs.
One thing is for sure is there are sure a bunch of folks working to get at every last Zen detail, so what remains will probably come out over the next few months before Zen’s full release date! Those compiler optimization manuals for Zen should already be out there, but protected under NDA types of agreements, but hopefully the benchmarking folks are already working on ways to test any new feature sets that AMD will be offering for Zen.
Probably not for this 4 core
Probably not for this 4 core complex/2 complex SKU as this may have only desktop/Server uses, so AMD probably has some other x86 Zen APU designs with 2 cores for 2017. And remember it’s the Zen core design that AMD claims will work from mobile to HPC and not so much the on die interconnects that even Intel varies in design across Intel’s many mobile and server/HPC x86 core variants. So AMD can and will offer APU designs that use the same Zen cores but it will be the on die interconnects/other uncore features that will vary between these 4 cores per complex based designs and any mobile variants that AMD will later have with less than 4 Zen cores.
I would guess that these initial 4 core minimum Die complexes can not be sliced and remain functional to keep from having any duplicated DRAM/other memory controller functionality pre-engineered into the cores so that any one or two could be sliced and operate independently. They are designed as 4 core complexes and can be scaled up in 4 core increments only. AMD will probably be designing 2 core + GPU cores APU variants and 4 core APU variants, and I would love to see some 6 core laptop APU variants, but that is up to AMD.
Really AMD looks like it’s focusing more on getting itself back into the better/higher margin Server/HPC/Workstations market first and this 4 Zen cores complex with 2 full complexes design may be simply half of a 16 core server variant used to get at the high end desktop market while AMD focuses more on getting those server products out the door ASAP and producing the great revenues. Intel does this too to a greater degree with Intel focusing on server/HPC SKU higher margins and taking some server variant and making them into high end consumer/E series SKUs.
So this first basic AMD desktop Zen based SKU is derived from a server SKU design, like Intel’s E series Desktop parts are derived from Server SKUs. It’s AMD making the best out of what design they have that utilize Zen cores in this early stages of AMD’s attempt to get back into the x86 based server market, so AMD is taking half a 16 core server variant and using it for a consumer enthusiasts’ SKUs and there is nothing wrong with that, if the performance of this Zen high end desktop SKU actually pans out.
I think the chip AMD might
I think the chip AMD might sell a bunch of is a 16 core 32 thread model.
Those should be able to match Intel best chip ever made (based on blender results), and if they undercut Intel by $500 (sell the chip for $1500 vs $2000) render farm house could save millions.
10,000 CPU nodes * $500 would be a $5,000,000 saving.
A 2.4ghz 16core Zen would easily match of beat the E5-2683 v4
Intel sell the 22 core E5-4669 v4 for $7000, so AMD 32core Zen should be an AMAZING chip. Specially if they can sell it for $5000
2017 should be very interesting for AMD….
I was really looking forward
I was really looking forward to Zen for my Windows 7 system, but they let us down there. Microsoft became jerks, and AMD refused to speak up.
Time to upgrade to a modern
Time to upgrade to a modern OS: Windows 10
If by modern you mean a
If by modern you mean a dumbed down, data mining os, I can do away with on the desktop as I already have a smartphone for that.
Just built a 6700K, 32GB
Just built a 6700K, 32GB DDR4, 1TB SSD, 8TB total storage, 1070 G1 system.
Used 8.1 since it is mkdern enough to handle everything 10 does but without the spyware terms.
10 is trash in every way. Its a regression.
Yes a metro modern TIFKAM
Yes a metro modern TIFKAM phone GUI/app ecosystem from Hell(renamed to UWP to obfuscate the TIFKAM taint), paired with an EULA for windows 10 that gives M$ the rights to your first born, and all your files/personal info. A big HELL NO to M$ and Windows 10! I’ll take Linux/Vulkan on my new PC/Laptop hardware or my purchasing days are over for any M$ OS based new PC/Laptop hardware.
You want my business after 2020 Linux OS based laptops OEMs, then you better get some Zen/Polaris Linux OS/Vulkan API Laptop SKUs offered, I do not want any Intel/Nvidia over priced Linux OS based laptop Kit, give me some fully monopoly free Linux OS/Vulkan API/Zen/Polaris laptop options and shut up and take my money!
Several disagreements between
Several disagreements between this article and Ian’s over at AnandTech.
Maybe a difference in what is meant by the ‘decoder’. An instruction decoder decodes already fetched instructions, it does not access the memory cache and memory while decoding.
The op cache holds previously decoded instructions, not values from memory.
However, instruction prefetching may speculatively prefetch both sides of a branch, and that does access the L1 instruction cache. Ian seemed to say L2 was involved as well.
Maybe a difference in what is meant by ‘increase’:
The total cache memory did increase compared to the APUs which have no L3, and compared to the non-APUs which had smaller L1 D cache. I think Carrizo had 96KB L1 I-cache but shared between both cores of a module, whereas Zen has 64KB L1 I-cache but private to one core. Ian says the L3 is a victim cache that does not duplicate L2, but does not prefetch either.
Have talked to a few people
Have talked to a few people about this, and AMD has not officially said one way or the other. We could see a mix of inclusive/exclusive with the L2 exclusive to the L3, which is a victim cache. As we get closer to launch we will receive more details.
Can anybody explain me the
Can anybody explain me the n-way cache associativity? How do you get to 8?
Each cache table and
Each cache table and associated cache slot/address (8 for example/n-way) is associated with a block of memory addresses(or lower Cache addresses) in a smaller cache memory size ratio to a larger DRAM memory size, or a larger size lower level cache, block of addresses. At the lowest level of last cache, the last Cache if it is associative cache will divide all of DRAM up into 8(for example), or n-way, blocks of address that map to one of the cache’s 8, or N-way, slots/divisions of Cache memory.
So Caches can themselves be divided up by higher levels of caches that have the same or different n-way associative relationship to a larger lower level cache on up the chain of cache levels until the Instruction and Data level 1 caches on a microprocessor.
so the n-way association is just a n-way table of cache slots that corresponds to a range of DRAM addresses, or a range of larger lower level of cache addresses. So the Instruction/Data L1 caches map to the larger lower level of cache(L2) that is divided n-ways to the cache above all the way down to DRAM which is the last level of memory below all the layers of cache memory above.
The idea of cache memory is to keep the most recently used or needed instructions data closer to the processor on a Cache level of memory that has a much wider block of connection bytes/BUS interface directly wired to the CPU than lower level cache or DRAM. Cache lines can have many Bytes of instructions/data that can be directly read into a CPUs Buffers, and these buffers are usually much wider than 64 bits, so whole cache lines can be read from a level one instruction or data cache to and from the CPU’s core/s or IO buffers.
The lower the level of cache on down to DRAM the more steps have to be taken to get the Instructions/Data fed into the CPU and the more latency inducing steps it takes to get the Instructions/Data to the CPU to be processed. It’s the job of the Cache memory subsystem and the and speculative units on the CPU to try and keep as much of the needed Instructions/Data in the cache level that is closest to the CPU as possible, so a lot of pre staging and other specialized CPU functional blocks are dedicated to the Cache and managing the cache using cache algorithms built into the CPUs hardware to manage cache and memory in the background to keep the CPUs execution units fed and fully utilized.
Whole PHD doctoral levels of research and development are dedicated to cache subsystem development on modern CPU systems! And whole teams are dedicated to creating a CPU’s cache memory subsytem processor/memory controllers on modern microprocessors.
Can anybody explain me the
Can anybody explain me the n-way cache associativity? How do you get to 8?
Not broadwelle but zen will
Not broadwelle but zen will compete with 4th gen stuff from intel easily. Not skylake not anything better than that. Still that is a good thing for us and for them.
I’ve got high hopes with Zen,
I’ve got high hopes with Zen, it seems like they took the best of the K10 design, and added the scalability/modularity of Bulldozer, then added a great deal of improvements, particularly in caches and predictions, then added SMT to be sure the core idles as little as possible.
The good news to me is that even if it doesn’t beat Intel’s HEDT models (though it should or come very close), if it’s priced right, it will great for everyone. Competition is what we have been missing in the CPU department since 2012 (Since AMD really stopped having answers to Intel’s high end).
Thanks for the informative
Thanks for the informative article Josh. It is such a shame that so many of the comments are posted by “anonymous”. They do nothing to contribute, and most of it has nothing to do with the article at hand.
Your mention of FMA4 led me
Your mention of FMA4 led me to Google it, seems that Zen CPUs may not have the instruction set – https://sourceware.org/ml/binutils/2015-08/msg00039.html
Yup, mentioned that here on
Yup, mentioned that here on the first page. "Of interest is the drop of support of FMA4."
The way I see it whether
The way I see it whether these are as powerful as the Intel I7’s or slightly less so, Zen will be giving AMD what it needs to put up a fight for market share which for me as a consumer is great because whether you are an AMD fan or not, more competition means lower prices.
I will most likely get one of these some time after release. Having a full quad core as the most basic release will be a major boon to customers like myself on the lower end of the price range as compared to Intel hashing out dual cores years after their day is over.
Do we know how HSA will do
Do we know how HSA will do for Zen?
I think it would be interesting if you could have 2 or more Zen APU that turned into CrossFire, plus having dedicated PCI 3.0 slots.
Possibly they could do this?
Server APU Opteron 2 socket board?
I’m cautiously optimistic in
I’m cautiously optimistic in the effect zen + vulkan + apu experience will give AMD in making respectable mid-budget gaming laptops with decent battery life.