
Bridging the Gap and Polling vs. IRQ
Bridging the Gap

XPoint sits in the middle of this 'gap', but the gap is way larger than this slide demonstrates!
Some other charts I put together for this piece were to try and visualize just what the 10x reduction in latency means to computing as a whole. First let's start with where CPU and RAM sat in relation to older formats up to and including spinning rust:
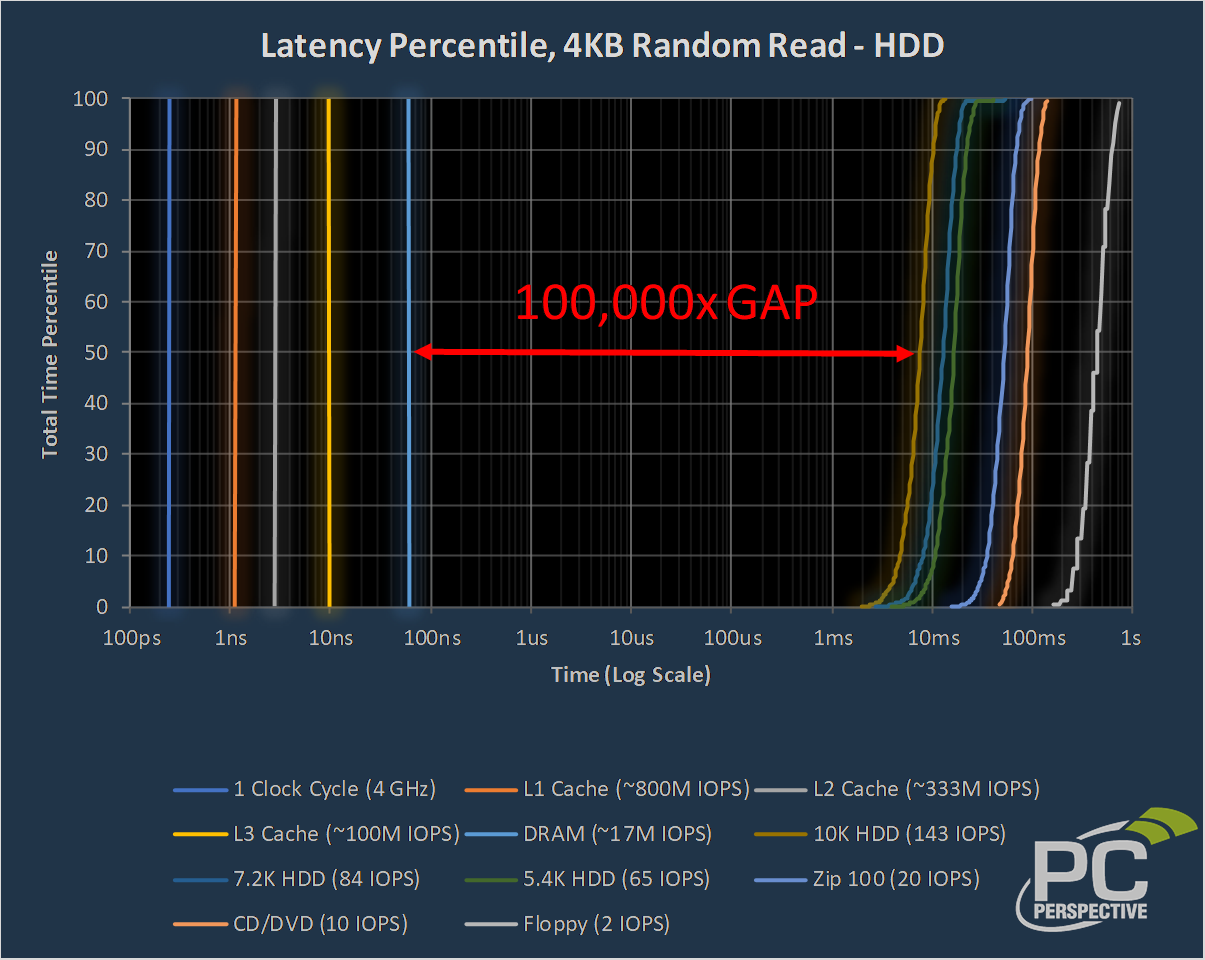
The various caches are on the left (starting with a single CPU clock tick!), and spinning media sits on the right. Yes, this storage nut actually busted out a Zip drive and a floppy drive just to give you fine folks a point of reference for moving to HDDs of various speeds (all three are also on this chart). Note that HUGE gap in latency between RAM and the fastest possible HDD? That, my friends, is the pain we all used to have to endure. 100,000 of pain.

I've now added in NAND SSDs. SATA (dark grey) has been around for the bulk of maturation of NAND flash, which is why we see that area starting 10x quicker than HDDs but stretching to 100X as the technology matured. PCIe NVMe parts (brown) are a bit quicker, but the gains are not huge here because at the end of the day those parts contain the same NAND chips that still take some time to respond to requests. Even with the newest fire breathing NAND SSD, we still have a 1,000x latency gap to the RAM.

The P4800X puts us on that dark blue line, shifting yet another 10x and closing the gap even further than the Samsung 960 PRO that made up the brown line preceding it..

For a simple estimation of where typical storage API calls through the Windows kernel can take us today, I ran a test on the fastest RAM disk software I could find. That got us nearly another 10x and fully bridges the gap. This is around the latency we should be able to see from a XPoint DIMM, if not even quicker once operating systems are better equipped to handle such fast NV storage.
Polling vs. IRQ
Alright, time to come clean. As it turns out, Windows is not able to reach 10us latencies when performing IO requests via the typical method. This is not specific to just Windows though, as XPoint devices have driven both Intel and Micron to release 'poll mode' drivers for Linux in order to help things on that side of the fence. The catch to polling the device will be intimately familiar to anyone who used to deal with PIO (Programmed I/O) vs. DMA (Direct Memory Access) modes in the early Windows days. As with polling, PIO accesses the device directly and asks (repeatedly) if data is ready, which as you can imagine, is murder on the CPU thread performing the request. DMA was born to solve this issue and was a blessing to multi-threaded systems. Using DMA, devices could place ready data into the RAM directly and then issue an interrupt request (IRQ) to inform the CPU that data was ready. The CPU was free to do other things (or sit idle) until it was interrupted by the request completion, saving on resources but adding a small bit of latency to the tail end of each request.
Unfortunately, with Optane, that 'small bit of latency' becomes very significant and consumes a fair percentage of the total latency of each request. Remember that chart I showed at the beginning of this article?
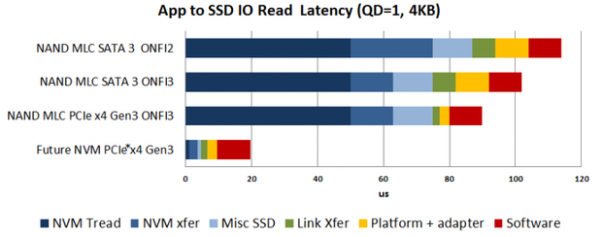
Notice how that red 'software' bar was so large? Here's what that looks like in practice:
Reads


Writes


The primary spot this issue hits the P4800X is in very low QD requests, and while it does hurt performance significantly, pushing it below its '<10us' spec, it is still a very fast product. Consistency was only minimally impacted, but the IRQ servicing added another 4-5us to each IO. Who would have thought it would take something like this to shine a huge light on how long Windows takes to context switch a CPU thread and service a storage related interrupt?
Do note that the 'poll' results obtained for this article were still using the Windows kernel and Microsoft 'InBox' NVMe driver, but our IO completion routine was altered in such a way as to avoid interrupt requests from being generated during those requests. In the future, a properly tuned driver could easily yield results matching our 'poll' figures but without the excessive CPU overhead incurred by our modified method of constantly asking the device for an answer.






the endurance and performance
the endurance and performance are impressive, and those prices are impressively high too!
Is it possible to get optane drives with slower speeds and same endurance? I mean, it seems like it would be cheaper and I’d be ok with SSD speeds we have now, just that endurance is really nice. I would literallly never replace the drive due to endurance.
Why would making it slower
Why would making it slower make it cheaper?
They make Optane drives that
They make Optane drives that are significantly cheaper at a slightly reduced endurance. They are called 900P.
Those are significantly
Those are significantly cheaper as compared to the new optane drives but are still WAY more expensive than sata ssds.
I think the idea is if the optane drive is much slower and still really good endurance that because it is slower it would mean even cheaper pricing.
Think about it, the faster devices are faster because hardware is more expensive to drive those devices faster.
Any real world testing ?
Like
Any real world testing ?
Like is this worth using in compile servers and workstation ?
If this save me 10 minutes a day in compile time, I would buy it.
But IOPS numbers doesn’t say much…
It really is workload
It really is workload dependent, and as we've found in our other research on Optane, it varies wildly by application. No specific real-world test would give you your answer unless we just happened to test your exact application on your exact hardware configuration. That said, we did note significant performance increases in similar applications – they are documented in this white paper.
Further, you should be able to monitor storage activity for your particular workload on your particular platform. If access times are totaling 10+ minutes for what you are doing, there's a good chance Optane will bring that number down significantly.
Many thanks again,
Many thanks again, Allyn.
It’s very gratifying to see Optane graduate
from questionable promises to production devices.
Guys trust me. Intel is
Guys trust me. Intel is making leaps and bound progress in making Optane win. I work for them. This is just the beginning. Prod Spec will only get better from here. End of 2018 there will be a Optane memory product along with storage.